- Parallel recursion for all inter-nodal communication
- Full web services API with key auth for query, stats, and upload
- Log forwarding via upload to web services (with compression/encryption)
- Post-batch processing plugin hook to allow plugins for processing raw batch files.
The biggest difference operationally will be that all ELSA installations must have both the node and the web code installed unless the node will only be forwarding logs. Logs will be loaded via the cron job that has previously only been used to execute scheduled searches. Other than that, neither end users nor admins will see much of a change in how they use the system. An exception is for orgs which had ELSA nodes in different locations which had high latency. Performance should be much better for them due to the reduced number of connections necessary.
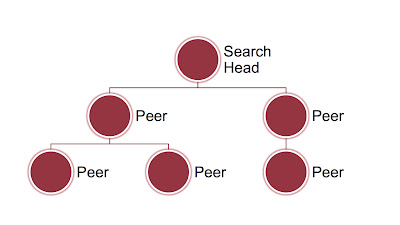
Architecturally, the new parallel recursion method allows for much more scalability over the older parallel model. I spoke about this at my recent talk for the Wisconsin chapter of the Cloud Security Alliance. The basic idea is that any node communicating with too many other nodes becomes a bottleneck for a variety of technical reasons: TCP handles, IO, memory, and latency.
{
"fowarding": {
"destinations": [ { "method": "url", "url": "http://192.168.2.2/upload", "username": "myuser", "apikey": "abc" } ]
}
}
On the search side, to extend queries from one node down to its peers, you would tell a node to add a peer it should query to the peer list in elsa_web.conf:
{
"apikeys": { "elsa": "abc" },
"peers": {
"127.0.0.1": {
"url": "http://127.0.0.1/",
"username": "elsa",
"apikey": "abc"
},
"192.168.2.2": {
"url": "http://192.168.2.2/",
"username": "elsa",
"apikey": "def"
}
}
This will make any queries against this node also query 192.168.2.2 and summarize the results.
Generally speaking, you want to keep the logs stored and indexed as close to the source that generated them, as this will lend itself naturally to scaling as large as the sources themselves and will conserve bandwidth for log forwarding (which is negligible, in most cases).
Orgs with just a few nodes won't benefit terrifically from the scaling, but the use of HTTP communication instead of database handles does simplify both encryption (via HTTPS) and firewall rules with only one port to open (80 or 443) instead of two (3306 and 9306). It's also much easier now to tie in other apps to ELSA with the web services API providing a clear way to query and get stats. Some basic documentation has been added to get you started on integrating ELSA with other apps.
Upgrading should be seamless if using the install.sh script. As always, please let us know on the ELSA mailing list if you have questions or problems!